Руководство: как закрыть сайт от индексации в поисковых системах? Работа с файлом robots.txt
— по оценке 62 пользователей
11 июля, 16:31

523868
1
На стадии разработки и/или редизайна проекта бывают ситуации, когда лучше не допускать поисковых роботов на сайт или его копию. В этом случае рекомендуется закрыть сайт от индексации поисковых систем. Сделать это можно следующим образом:
Закрыть сайт от индексации очень просто, достаточно создать в корне сайта текстовый файл robots.txt и прописать в нём следующие строки:
User-agent: Yandex
Disallow: /
Такие строки закроют сайт от поискового робота Яндекса.
User-agent: *
Disallow: /
А таким образом можно закрыть сайт от всех поисковых систем (Яндекса, Google и других).
Отдельную папку можно закрыть от поисковых систем в том же файле robots.txt с её явным указанием (будут скрыты все файлы внутри этой папки).
User-agent: *
Disallow: /folder/
Если какой-то отдельный файл в закрытой папке хочется отдельно разрешить к индексации, то используйте два правила Allow и Disallow совместно:
User-agent: *
Аllow: /folder/file.php
Disallow: /folder/
Всё по аналогии.
User-agent: Yandex
Disallow: /folder/file.php
Проще всего осуществить проверку в рамках сервиса «Пиксель Тулс», бесплатный инструмент «Определение возраста документа в Яндексе» позволяет ввести URL списком. Если документ отсутствует в индексе, то в таблице будет выведено соответствующее значение.
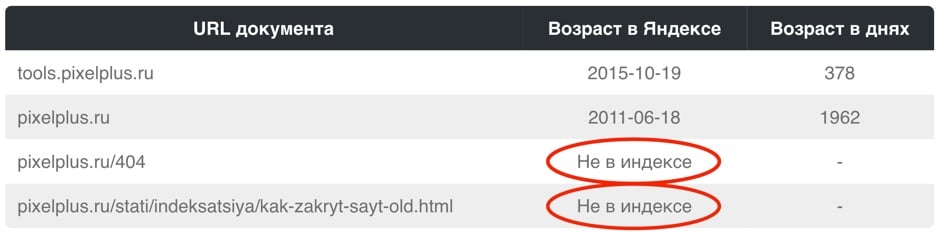
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Картинки форматов jpg, png и gif могут быть запрещены к индексации следующими строчками в robots.txt:
User-Agent: *
Disallow: *.jpg
Disallow: *.png
Disallow: *.gif
У каждого поддомена на сайте, в общем случае, имеется свой файл robots.txt. Обычно он располагается в папке, которая является корневой для поддомена. Требуется скорректировать содержимое файла с указанием закрываемых разделов с использованием директории Disallow. Если файл отсутствует — его требуется создать.
Дубль на поддомене может стать проблемой для SEO при использовании CDN. В данном случае рекомендуется, либо предварительно настроить работу атрибута rel="canonical" тега <link> на основном домене, либо создать на поддомене с CDN (скажем, nnmmkk.r.cdn.skyparkcdn.ru) свой запрещающий файл robots.txt. Вариант с настройкой rel="canonical" — предпочтительный, так как позволит сохранить/склеить всю информацию о поведенческих факторах по обоим адресам.
У каждой поисковой системы есть свой список поисковых роботов (их несколько), к которым можно обращаться по имени в файле robots.txt. Приведем список основных из них (полные списки ищите в помощи Вебмастерам):
Поисковая система Яндекс также поддерживает следующие дополнительные директивы в файле:
«Crawl-delay:» — задает минимальный период времени в секундах для последовательного скачивания двух файлов с сервера. Также поддерживается и большинством других поисковых систем. Пример записи: Crawl-delay: 0.5
«Clean-param:» — указывает GET-параметры, которые не влияют на отображение контента сайта (скажем UTM-метки или ref-ссылки). Пример записи: Clean-param: utm /catalog/books.php
«Sitemap:» — указывает путь к XML-карте сайта, при этом, карт может быть несколько. Также директива поддерживается большинством поисковых систем (в том числе Google). Пример записи: Sitemap: https://pixelplus.ru/sitemap.xml
Также, можно закрыть сайт или заданную страницу от индексации с помощь мета-тега robots. Данный способ является даже предпочтительным и с большим приоритетом выполняется пауками поисковых систем. Для скрытия от индексации внутри зоны <head> </head> документа устанавливается следующий код:
<meta name="robots" content="noindex, nofollow"/>
Или (полная альтернатива):
<meta name="robots" content="none"/>
С помощью meta-тега можно обращаться и к одному из роботов, используя вместо name="robots" имя робота, а именно:
Для паука Google:
<meta name="googlebot" content="noindex, nofollow"/>
Или для Яндекса:
<meta name="yandex" content="none"/>


Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов






Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.
зарегистрируйтесь на сайте, используя e-mail.
Зарегистрироваться, используя e-mail: