Ошибки индексации Яндекса и Google: почему исключены страницы и что делать?
— по оценке 78 пользователей
27 февраля, 09:51

16271
10
19
Нет идеальных сайтов, в том числе с технической точки зрения и восприятия поисковыми системами!
Ты думаешь, что закрыл от индексации все служебные и «мусорные» страницы в файле robots.txt, и можно больше не возвращаться к этому вопросу? Не, нифига!
Google запросто берет и игнорирует директивы закрытия:
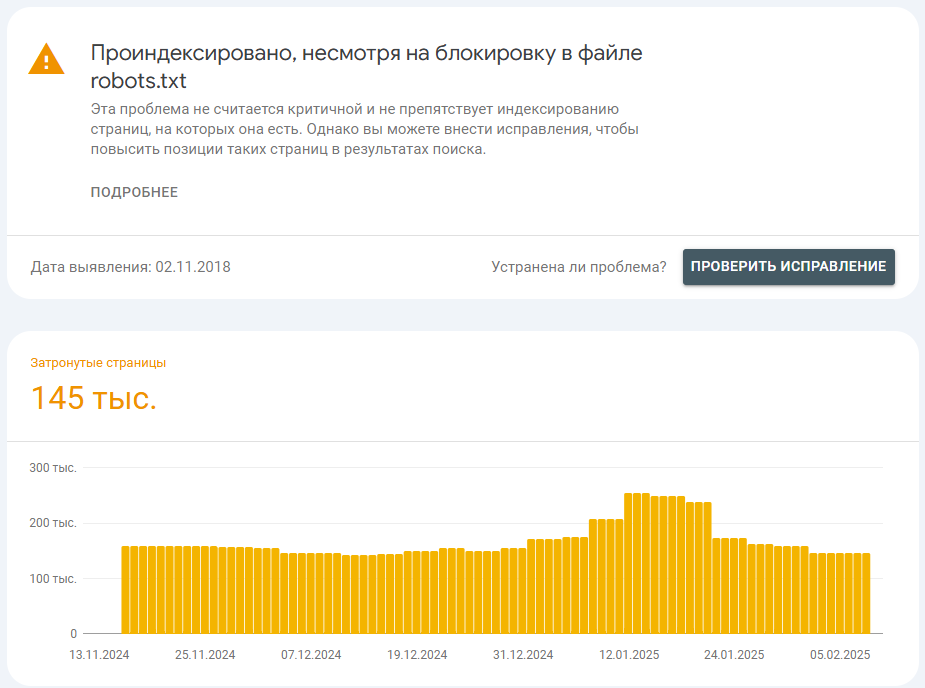
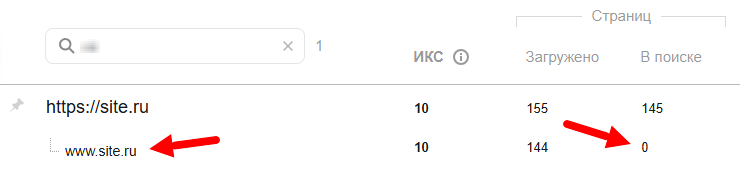
Только представьте — 145 тысяч страниц, которые вы когда-то закрыли от индексации, прямо сейчас находятся в выдаче поисковой системы. И самое интересное: всего страниц под спрос примерно в 2 раза меньше.
У вас что, проблемы с ранжированием в Google? Наверное все дело в факторах E-E-A-T. 😉
Поисковые системы предлагают справки, где дано пояснение по каждому из статусов, в частности:
На практике же далеко не каждый SEO-специалист может четко ответить, какие необходимо предпринять меры при наличии страниц, исключенных из индекса с тем или иным статусом.
Предлагаем на конкретных примерах разобраться, почему поисковые системы могут удалять страницы из индекса или напротив — добавлять те, которые мы вроде бы закрыли от индексации и, которые нам доступны в панели Яндекс Вебмастер и Google Search Console.
И, самое главное, постараемся ответить на вопрос «А что делать?» по каждому статусу, чтобы вы могли использовать этот материал как инструкцию.
Яндекс Вебмастер предоставляет возможность оценить, насколько эффективно ваш сайт находится пользователями. С помощью этого сервиса вы можете отслеживать и анализировать индексацию страниц, их позиции в поисковой выдаче, а также контролировать техническое состояние ресурса.
Причины исключения страниц из индекса и статус можно найти:
И отфильтровать по статусу или даже загрузить полный список.
Что значит?
Статус означает наличие переадресации для страницы сайта. При этом здесь фиксируются редиректы:

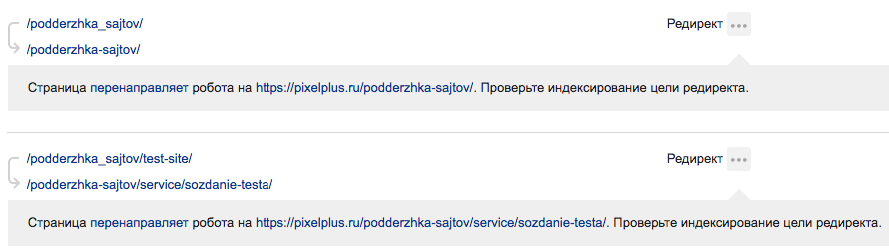
Какой вывод и что делать?
Что значит?
Дубли страниц на сайте могут возникать по разными причинам:
При этом, даже если вы предусмотрели все основные пункты, вряд ли гарантированно обезопасите себя от появления таких страниц в панели Вебмастер.
Яндекс просто добавляет в индекс URL-адрес с заглавной буквой, а затем признает его дублем и, по идее, с этим тоже необходимо что-то делать:
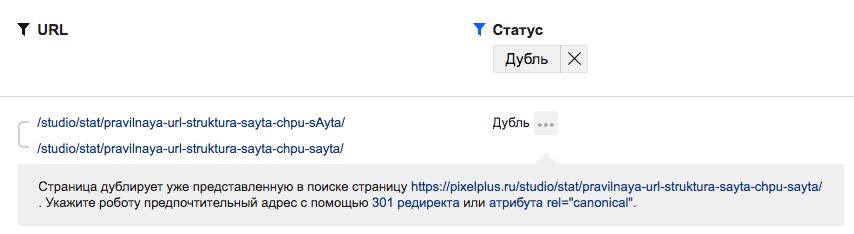
Какой вывод и что делать?
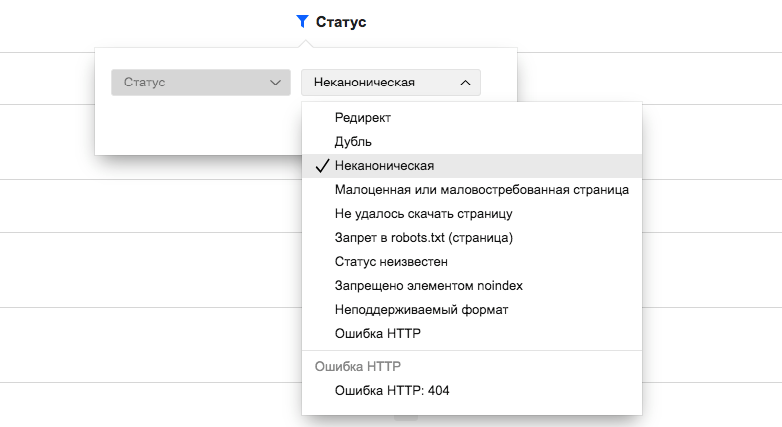
Что значит?
Список страниц, которые исключены из индекса за счет настроенного ранее атрибута rel="canonical" для документов, в рамках которых дублируется контент.
Важно иметь в виду, что если страницы дублируют друг друга частично, вряд ли поисковики учтут ваши пожелания, такие страницы будут одновременно находится в поиске.
Какой вывод и что делать?
Наличие дублей на сайте не является критичной проблемой, когда вы знаете об их существовании и обозначаете это поисковым системам. Конечно, лучше обойтись без дублей, но когда это технически невозможно, укажите поисковикам канонический URL-адрес и двигайтесь дальше, решая более важные задачи с точки зрения KPI.
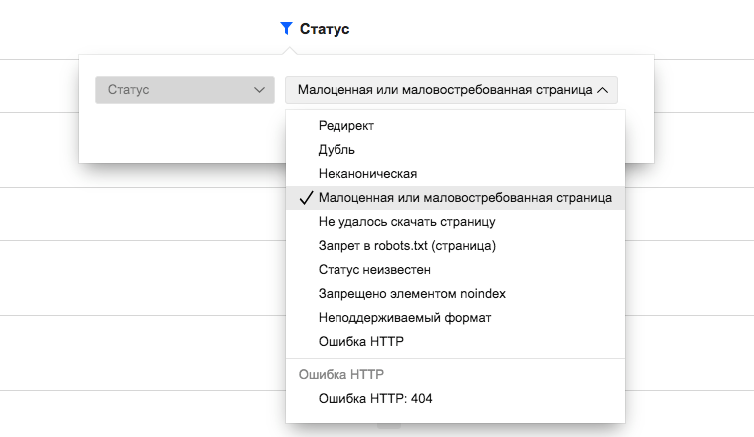
Что значит?
Давайте разберемся в понятиях:
Какой вывод и что делать?
Кстати, на нашем сайте отсутствуют документы с таким статусом.
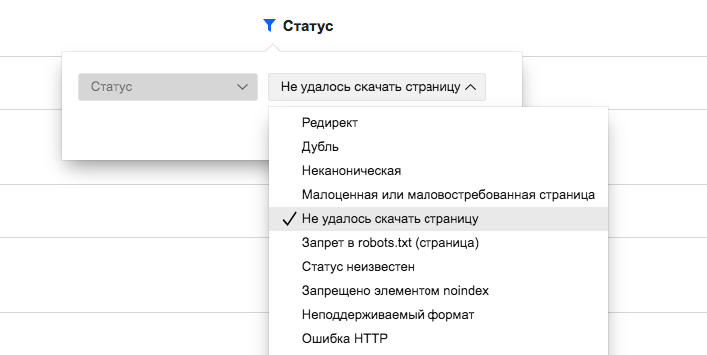
Что значит?
Распространенный формат страниц в этом списке:
Что делать?
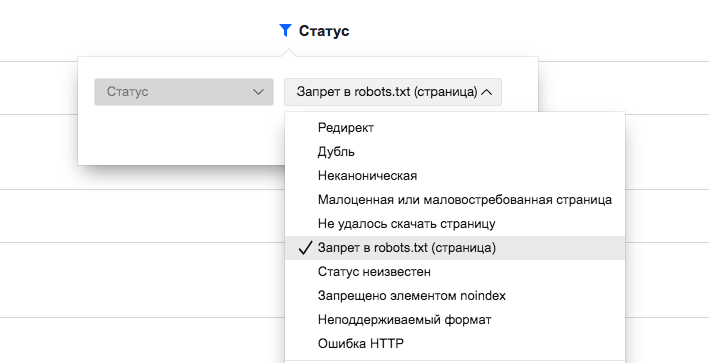
Что значит?
Здесь нет каких-либо секретов, в списке будут отображаться страницы, которые запрещены к индексации в файле robots.txt.
Какой вывод и что делать?
Важно своевременно выявлять подобные недочеты, а также быть уверенным, что в файле robots закрыты только ненужные простым пользователям документы сайта.
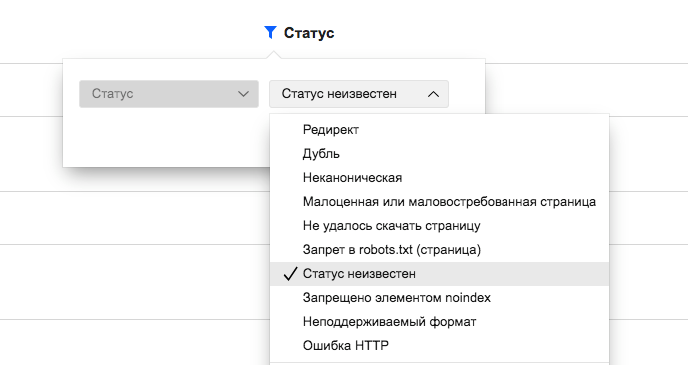
Что значит?
Этот статус прямо говорит нам о том, что у поискового робота нет актуальных данных для страницы.
Любопытно то, что в списке можно найти различные варианты URL: закрытые от индексации в robots.txt, закрытые meta-тегом robots и т.д.
Что делать?
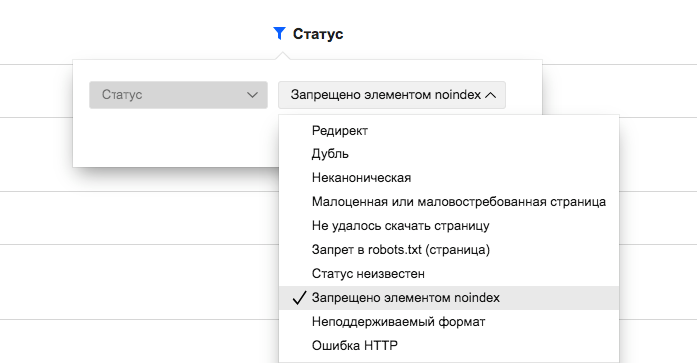
Что значит?
Как и в случае с запретом в robots.txt, здесь отображается список страниц с другим, более корректным форматом закрытия страниц от индексации, если мы говорим об обоих основных поисковых системах.
Что делать?
Убедиться, что в списке нет важных и продвигаемых страниц, которые могли быть закрыты по ошибке.
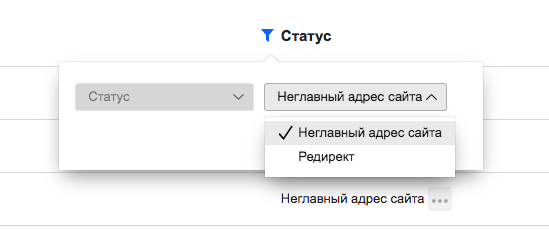
Что значит?
Данный пункт фигурирует только у проектов, которые НЕ являются главным зеркалом сайта в глазах поисковой системы.
Какой вывод и что делать?
Никаких действий предпринимать не требуется.
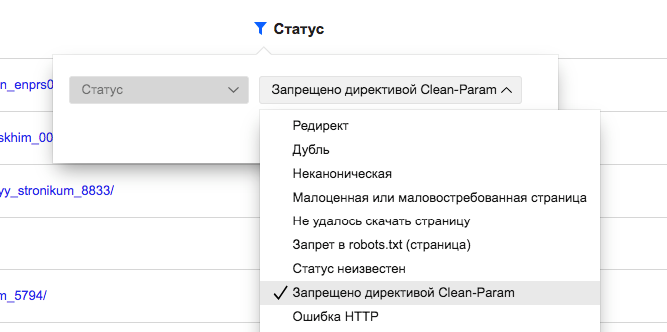
Что значит?
Яндекс обозначает этим статусом страницы, которые исключены из индекса посредством обработки директивы Clean-param в файле robots.txt.
Эта директива используется для устранения дублей страниц с GET-параметрами, которые нельзя закрывать от индексации (например, utm-метки), а также часто встречается у сайтов на Tilda, из-за ограничений в полноценном редактировании файла robots.txt.
Какой вывод и что делать?
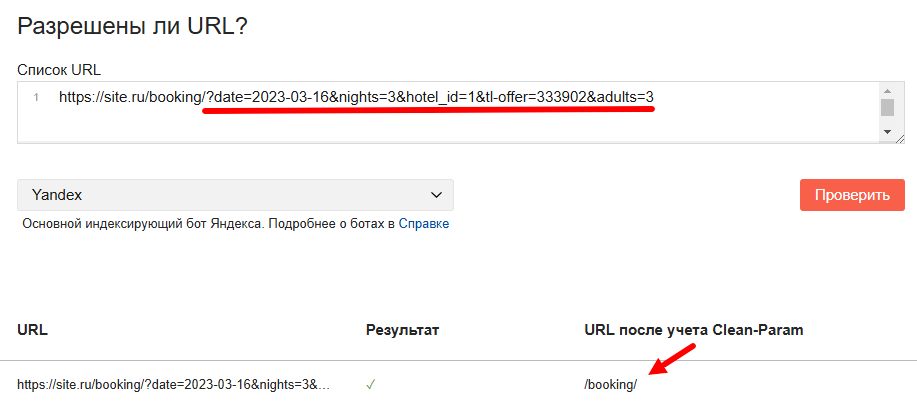
Единственное, в чем вы должны быть уверены, что директива Clean-param настроена корректно для конкретных URL, которые вы хотите исключить из индекса.
Проверить это можно инструментом панели Вебмастер: «Анализ robots.txt», достаточно дождаться загрузки содержимого файла, вставить нужную ссылку и убедиться, что из URL убираются все GET-параметры, особенно если их несколько!
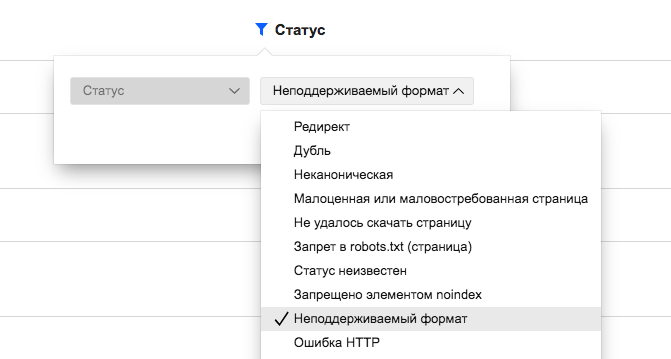
Что значит?
В списке страниц зачастую фиксируются страницы, на которых отсутствует заголовок Content-Type.
Например, XML-карта сайта:
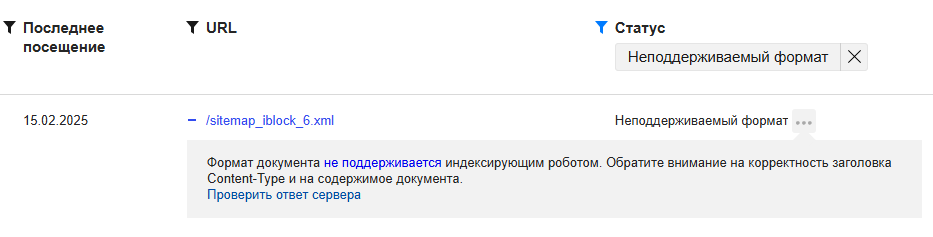
Что делать?
Если вдруг в списке оказалась один из страниц сайта, которая доступна пользователям, рекомендуется проверить ответа сервера и, при наличии проблем, принять необходимые меры по их устранению
Скрин временно отсутствует, нам не удалось найти ошибку у проектов на SEO.
Что значит?
Статус означает, что поисковый робот при обращении к сайту не смог установить соединение с сервером.
Что делать?
Если сайт открывается без каких-либо проблем, Яндекс через какое-то время переобойдет страницы и сменит статус на корректный (но лучше не ждать, и направить список URL на переобход).
Что значит?
В данном статусе объединяются все ошибки ответа сервера, но чаще всего преобладают страницы с кодом 404.
Также в этом же окне можно выбрать конкретный код ошибки:
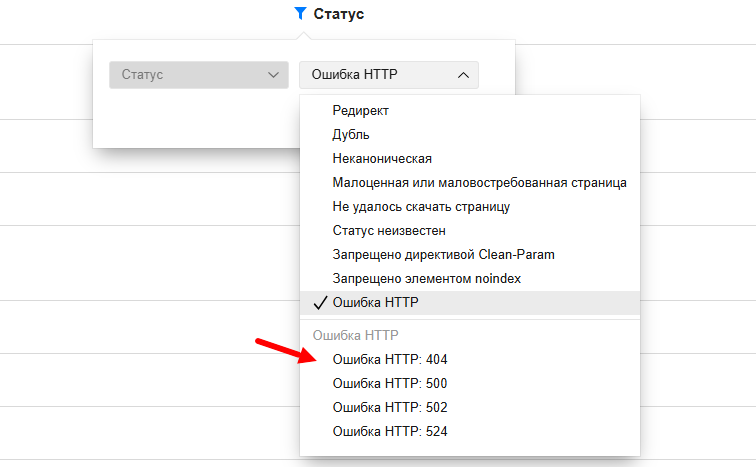
Какой вывод и что делать?
Некорректная ссылка, оставленная пользователем на форуме или внутренняя ссылка, также ведущая на несуществующую страницу — все подобные URL гарантированно окажутся в этом списке.
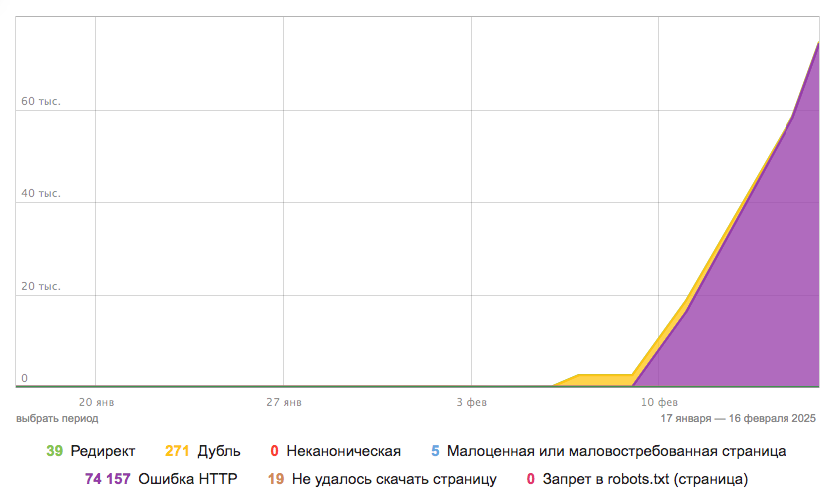
Рекомендуем убедиться в работоспособности сайта, а также проверить его на предмет взлома.
Google Search Console — это бесплатный инструмент, который позволяет отслеживать, как ваш сайт отображается в поисковой выдаче Google, улучшать контент и исправлять возможные ошибки. При этом регистрация в сервисе не является обязательной для того, чтобы ваш сайт был проиндексирован Google.
Что значит?
Очевидная проблема, связанная с доступностью страниц и кода, который отдает сервер.
Какой вывод и что делать?

Но при проверке сервер отдает код 500:
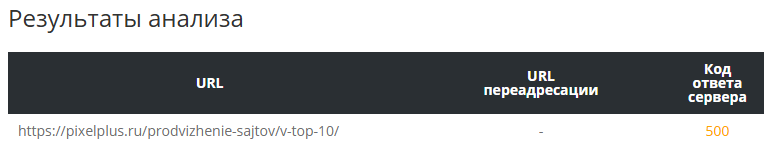
Не сказать, что это критическая проблема, но лучше, чтобы код ответа сервера был корректным.
Что значит?
Ошибка возникает при наличии на сайте страниц, для которых некорректно настроена переадресация.
Например, цикличный 301-редирект:

Что делать?
Выяснить, на каком этапе при настройке переадресации для URL была совершена ошибка и исправить ее.
Что значит?
Понятный статус — страницы, которые закрыты от индексации в файле robots.txt отображаются в этом разделе Google Search Console.
Какой вывод и что делать?
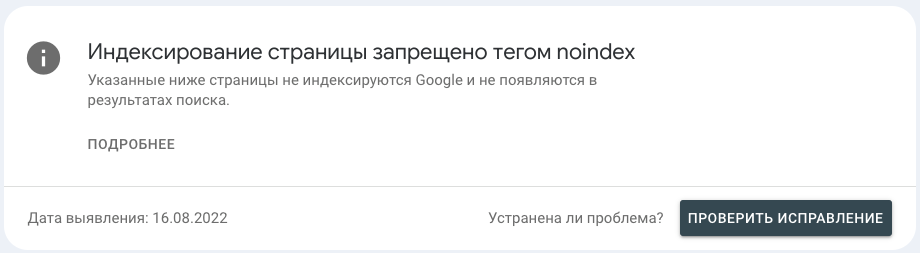
Что значит?
Альтернативный файлу robots.txt и предпочтительный с точки зрения Google способ закрытия страниц от индексации, meta-тег [meta robots].
Что делать?
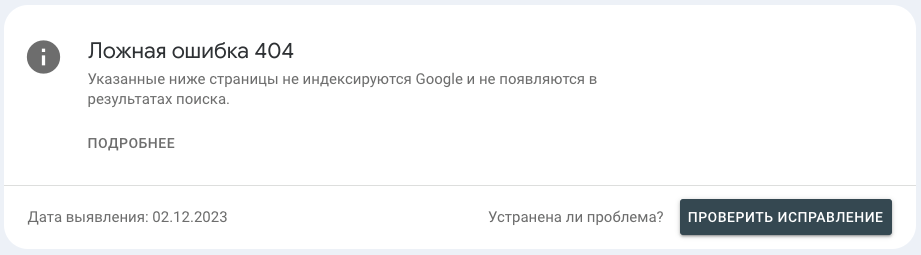
Что значит?
Данная ошибка возникает в ситуациях, когда посетитель сайта видит на странице информацию, что ее не существует, при этом сервер отдает код ответа 200.
Пример:

В некоторых случаях статус может быть присвоен страницам, на которых частично или полностью отсутствует контент.
Какой вывод и что делать?
а) Если они не привлекают органический трафик, лучше их скрыть с сайта.
б) Если они привлекают трафик, оптимально доработать их таким образом, чтобы поисковая система не интерпретировала ее как несуществующую, а пользователи получали достойный ответ на свой запрос и не возвращались в поисковую выдачу.
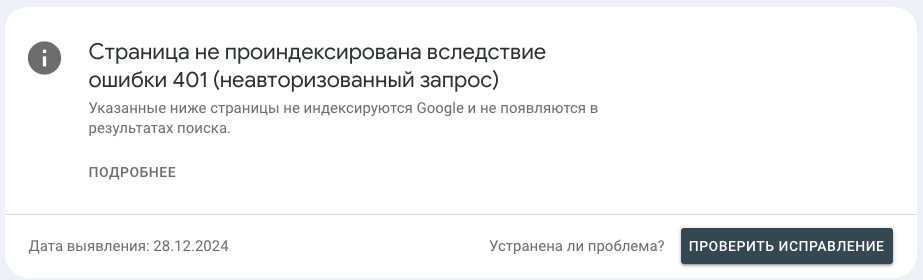
Что значит?
Данный статус указывает на то, что на сайте присутствуют страницы, которые требуют авторизации (контент доступен после авторизации).
Самый распространенный тип страниц с этим статусом — URL, которые НЕ закрыты от индексации, при этом относятся к скрытым категориям сайта.
Например, раздел и внутренние страницы, созданные для партнеров компании с товарами, где цена может быть отличной от общедоступных (оптовые).
Что делать?
Каких-либо дополнительных манипуляций здесь не требуется, тем не менее мы рекомендуем такие страницы закрывать от индексации, чтобы гарантированно исключить их попадание в индекс.
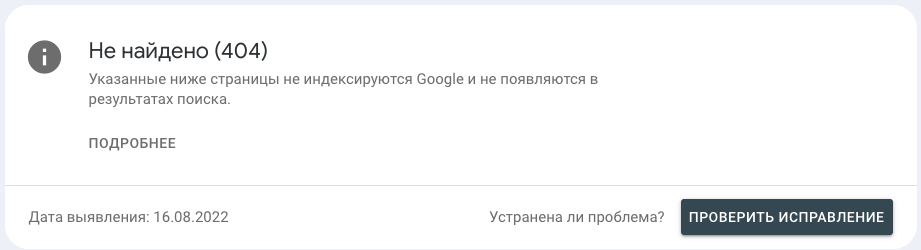
Что значит?
Страницы сайта с кодом ответа сервера 404.
Какой вывод и что делать?
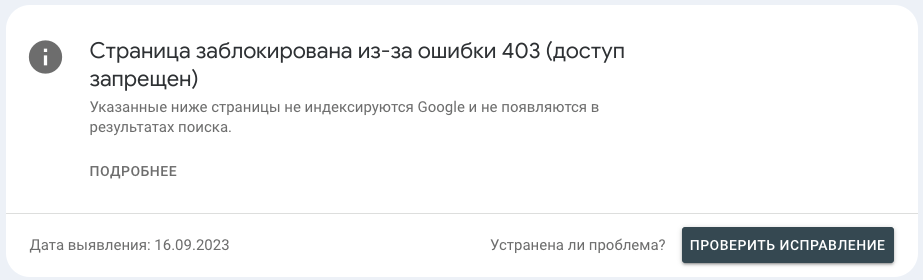
Что значит?
Ошибка 403 означает, что у поискового робота есть ограничение или отсутствие доступа к контенту страницы.
Какой вывод и что делать?
Не самая распространенная ошибка, тем не менее оцениваем количество таких URL и что за страницы фигурируют в списке, на предмет реальной ошибки со стороны сайта.
В большинстве случаев устранить ошибку можно только с привлечением грамотного специалиста отдела технической поддержки сайта.
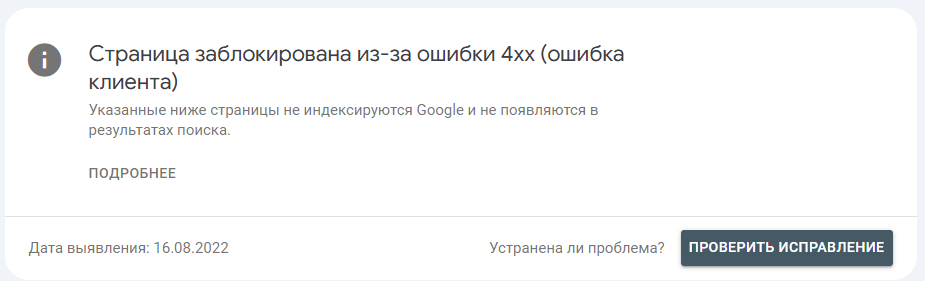
Что значит?
Дословно:
Суть ошибки заключается в том, что Google (как, вероятно, и Яндекс) без проблем интерпретирует наиболее распространенные кода ответа сервера (404, 403, 401) и не тратит свои ресурсы не более редкие, объединяя их в общий формат.
А кодов, которые начинаются с 4хх порядка 30 штук:
Мне больше всего нравится: 418 I’m a teapot («я — чайник»), а вам? 😂
Какой вывод и что делать?
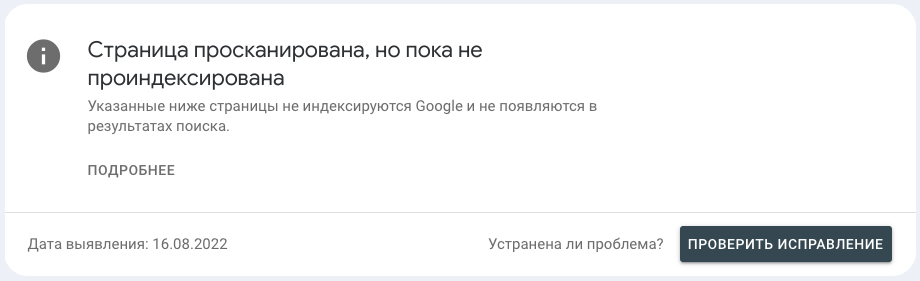
Что значит?
Это значит, что поисковая система знает о существовании страницы, она была просканирована, но на текущий момент не добавлена в индекс.
Сюда попадают все новые страницы сайта, при этом некоторые из них могут находиться тут достаточно большое количество времени.
Если рассматривать интернет-магазин со сложной структурой каталога и большим ассортиментом, здесь гарантированно будут преобладать детальные страницы карточек товаров.
Также, здесь можно найти ссылки на изображения в формате .webp, но это скорее недочет на стороне Google.
Какой вывод и что делать?
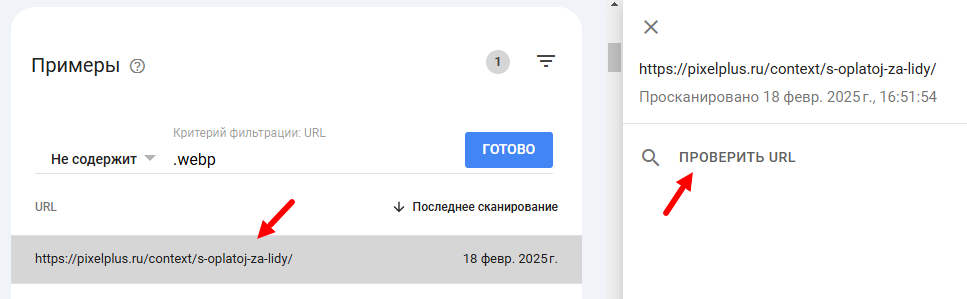
Зачастую бывает так, что данные не актуальны и страницы на самом деле находятся в индексе.
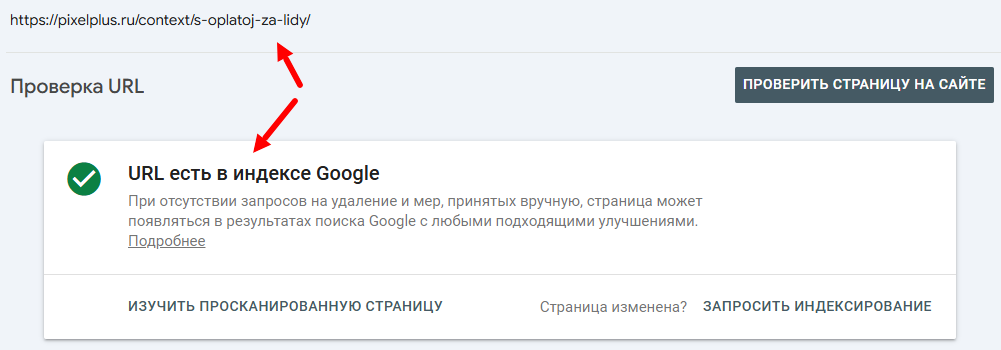
Дополнительно можно проверить страницы прямо через выдачу Google, введя URL-адрес в строку поиска с оператором [site:]:
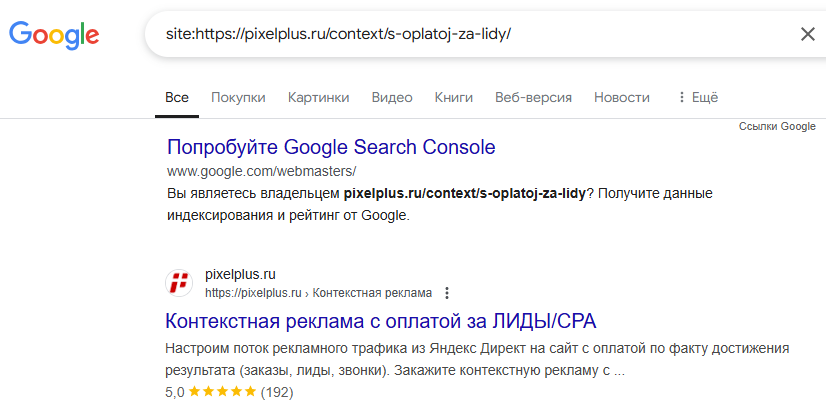
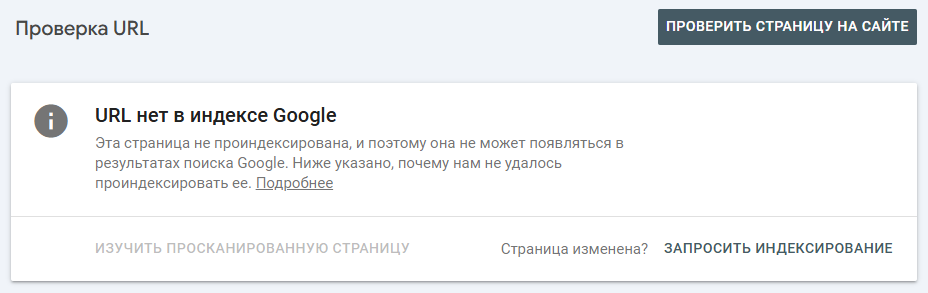
Рекомендуем:

Что значит?
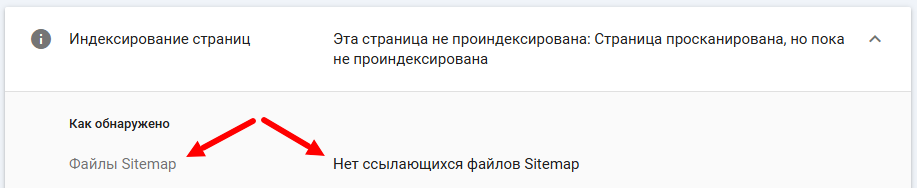
Это значит, что поисковая система нашла эту страницу, но по тем или иным причинам она не была просканирована (к слову о краулинговом бюджете).
Какой вывод и что делать?
Можно просто ждать, но если в списке фигурируют продвигаемые страницы, которые при попадании в индекс дадут вам рост трафика и лиды, рекомендуем в первую очередь оценить их уровень вложенности, присутствие в XML-карте сайта, а также общее количество ссылающихся на них документов.
Что значит?
Страницы, которые поисковик пометил как альтернативу уже проиндексированным и корректно указывающим на канонический URL-адрес.
Что делать?
Посмотреть список страниц и убедиться, что нет ошибочно выбранных каноническими (на случай, если у вас на сайте ошибка в настройка атрибута rel="canonical").
Что значит?
Это страницы, которые являются копиями других страниц сайта, при этом вы не обозначили это поисковику и сам Google выбрал канонической другой URL-адрес.
Что делать?
Что значит?
Из названия статуса можно сделать выводы, что вы в рамках атрибута rel="canonical" прямо указываете поисковой системе, какая страница является канонической, а Google не согласен и добавил в индекс документ на свое усмотрение.
Вывод.
Самый распространенный формат страниц — постраничная навигация у интернет-магазинов, когда в атрибуте ссылка сама на себя, а Google выбираем канонической основной URL-адрес раздела.
Что значит?
В списке отображаются страницы, для которых была настроена переадресация на другие URL.
Страницы с этим статусом не будут проиндексированы.
Что делать?
Достаточно убедиться, что в списке нет актуальных продвигаемых URL, которые могли туда попасть по ошибке.
Что значит?
То, о чем мы говорили в самом начале статьи — закрыть страницы от индексации в файле robots.txt иногда недостаточно, чтобы исключить их из индекса Google.
Чаще всего в этом списке появляются страницы сортировки и/или фильтрации, доступные в рамках листингов товаров, а также страницы постраничной навигации, если они не оптимизированы и закрыты в файле robots.txt.
Google якобы следует инструкциям в файле, тем не менее URL могут быть проиндексированы, если на них есть ссылки как внутри проектах, так и на других ресурсах.
Что делать?
Что значит?
Страницы фигурируют в индексе Google, но робот поисковика не смог обработать их содержимое.
Что делать?
 Telegram-канал Сергея Просветова
Telegram-канал Сергея Просветова
🚀 Узнай первым секреты SEO и прокачай свои скиллы!




Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов











Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.
Зарегистрироваться, используя e-mail: