Кворум и попадание в SERP в Яндексе
— по оценке 16 пользователей
15 марта, 21:22

26809
0
5
Документы могут присутствовать в результатах выдачи поисковой системы без вхождения ряда слов из запроса в его текст и тексты входящих ссылок. Порой, в процесс поиска причин данного поведения SEO-специалисты наделяют значимыми качествами meta-тег Description, атрибут alt картинки и т.д., что некорректно для Яндекса. Приведем основные причины попадания документов в выдачу Яндекса, когда в тексте документа и входящих на него ссылках ЗАВЕДОМО отсутствуют слова из поискового запроса.
Как известно, для попадания в выдачу по каждому запросу, документ должен набрать (пройти) определенный кворум.
Кворум — необходимая доля суммарного веса (IDF) слов из поискового запроса, которая должна присутствовать в тексте документа и/или текстах входящих на него ссылок для попадания в результаты поиска (SERP).
Как следует из определения, для попадания в результаты выдачи, документ должен содержать в себе и/или текстах входящих на него ссылок все или заданную минимальную долю веса слов из запроса. Доля высчитывается как функция от длины запроса (в словах) и весов слов входящих в него по формуле представленной ниже (Рис.1), где:
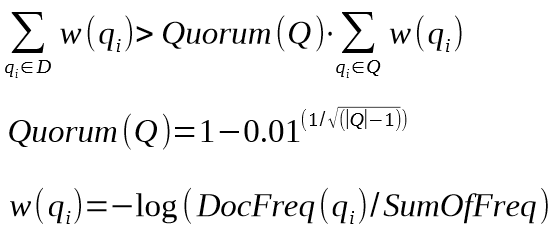
Рис. 1. Формула для кворума (доли веса) из презентации одного из разработчиков Яндекса — Дениса Расковалова. Формула известна и сильно ранее, в частности встречается и в статье разработчиков 2004 года.
Численный параметр 0.01 из формулы носит название мягкости и может меняться в зависимости от настроек поисковой системы. Имеются определенные основания полагать, что значение мягкости в Яндексе может быть отлично от 0.01 и принимать значение 0.06. Для двух данных значений была вычисленная минимальная доля веса (кворум), которая должна быть найдена для документа для включения в результаты выдачи (Рис. 2).
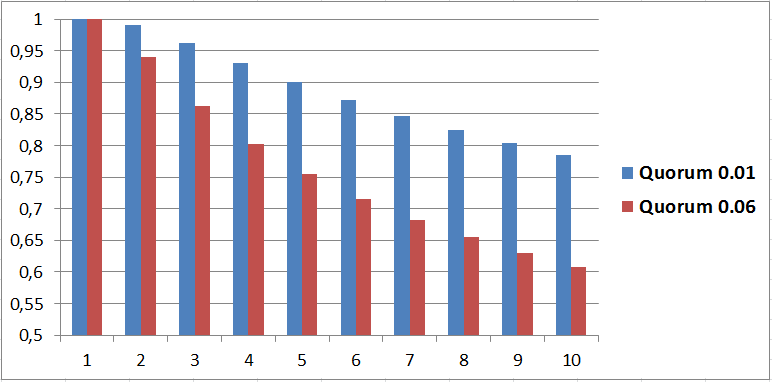
Рис. 2. Вычисленное значение Quorum для двух значений мягкости — 0.01 (синие столбцы) и 0.06 (красные столбцы) в зависимости от длины запроса в словах. По оси Y — минимальная доля суммарного веса для прохождения кворума, по X — число слов в запросе от 1 до 10.
Как видно из гистограммы, для включения в ранжирование документа по пятисловному поисковому запросу (при коэффициенте мягкости 0.06) достаточно чтобы в нём встречалось 4 слова из запроса (при равенстве весов всех слов из запроса). Более того, правила прохождения кворума могут меняться в зависимости от запроса и числа найденных по нему документов.
Таким образом, мы приходим к первому возможному случаю, когда в тексте документа и/или текста входящих на него ссылок встречаются не все слова из запроса, а только часть, но этой части оказывается достаточно для прохождения кворума. Пример представлен ниже (Рис. 3):
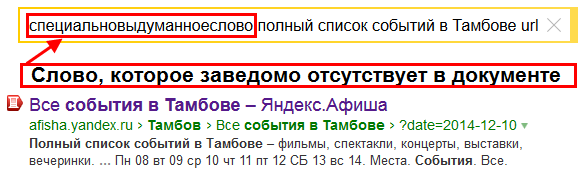
Рис. 3. Демонстрация прохождения документа по кворуму в Яндексе со словом, которое заведомо отсутствует в его тексте и анкорах ссылок.
Второй распространенный случай присутствия документа в SERP без прямого вхождения слов из поискового запроса — это вхождение СИНОНИМОВ ЗАПРОСА в текст и анкоры входящих на него ссылок.
Кроме того, не все синонимы подсвечиваются в сниппете, что может вводить SEO-специалистов в заблуждение. Определить, что документ найден в Яндексе с помощью синонимов можно используя GET-параметр «nosyn». На иллюстрациях ниже (Рис. 4 и Рис. 5) представлен как раз такой пример, когда при обработке поискового запроса [мебель офис] в переколдовку добавляется слово «офисная», в результате чего документы с вхождением таких фраз как «офисная мебель» оказывается найденными. При добавлении GET-параметра «nosyn» — документ пропадает из выдачи (Рис. 5).

Рис. 4. Демонстрация попадания документа в выдачу Яндекса за счёт синонимов.

Рис. 5. Использование GET-параметра «nosyn» для проверки того, что документ найден с помощью синонимов.
Важно отметить, что корректно говорить о синонимах ЗАПРОСА, а не о синонимах СЛОВ из него, так как в зависимости от точной формулировки запроса одно и то же слово может, как является синонимом, так и не быть таковым.
К данному же случаю стоит отнести и прочие примеры, когда документ оказывается найден из-за механизма переколдовки поискового запроса (к словам из запроса, в зависимости от его содержимого, добавляются: синонимы, аббревиатуры, перевод и т.д.)
Третий, весьма распространенный случай попадания в выдачу без вхождения слов из запроса, это вхождение всех или некоторых слов в виде транслита в URL-документа.
Интересным здесь также оказывается то, что не все виды транслита, которые понимает поисковая система, подсвечиваются. Ниже (Рис. 6) представлен аналогичный пример, когда документ оказывается релевантным запросу [шуба] за счёт вхождения в URL конструкции вида «wuba».

Рис. 6. Ранжирование документа за счёт вхождения в URL запроса без подсветки самого транслита в адресе.
Стоит отметить, что вхождение транслита слов из запроса в URL повышает вероятность документа набрать кворум в Яндексе.
Известно, что поисковая система Яндекс фиксирует совокупность поисковых запросов, по которым осуществлялись заходы на заданный документ. Данная совокупность запросов носит название запросного индекса и презентация с конференции AllInTopConf. Существует точка зрения, что документ может быть найден и фигурировать в выдаче только за счёт запросного индекса. Текущие проверки не позволяют безоговорочно поддержать её, но наблюдения за данным аспектом продолжаются.
Поисковые системы включают в текстовый индекс содержимое не всех зон документа. В частности, известно, что Яндекс не осуществляет поиск по таким зонам как: мета-теги Description, Keywords, атрибуты alt и title картинок и ряду других. Но, данные утверждения могут перестать быть корректными с течением времени. Требуется проводить регулярные наблюдения за выдачей и индексатором. В частности, на текущий момент имеется возможность производить поиск по некоторым служебным зонам.
Иногда, аспекты описанные выше не принимаются во внимание и SEO-специалисты могут делать ошибочные выводы. В частности по запросу [безопасные коляски трансформеры] находится документ, в сниппете которого фигурирует текст из meta-тега Description (Рис. 7). Слово «безопасные» же отсутствует в тексте документа и входящих на него ссылках. Может Description начал давать плюс? Нет, на самом деле, здесь срабатывает мягкость и документ проходит кворум без этого слова. Данное утверждение можно проверить заменив слово «безопасные» на произвольное, скажем «вурбалакийсын» (Рис. 8).

Рис. 7. Документ с вхождением в сниппет слова «безопасные».
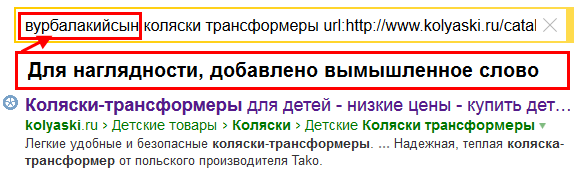
Рис. 8. Ранжирование документа за счёт срабатывания мягкости.
Также, убедиться к отсутствии текста из meta-тега Description в текстовом индексе можно задав фразу из Description в кавычках (Рис. 9).

Рис. 9. Отсутствие заданного документа в выдаче по тексту точно составленному из Description.
Надеемся, что рассмотренные выше примеры помогут SEO-специалистам производить аналитику выдачи и успешно продвигать сайты самостоятельно.




Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов













Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.
Зарегистрироваться, используя e-mail: