Алгоритм Яндекса «Королёв»
— по оценке 3 пользователей
28 августа, 23:15

24975
0
6
Искусственная нейронная сеть со скрытыми слоями, «длинный хвост», дополнительный индекс и поиск с учётом семантического соответствия («смысла»).
Хм, серьёзно? Вместе разбираемся с новым алгоритмом Яндекса.

Во второй половине августа Яндекс запустил новый алгоритм с названием «Королёв». Официальный анонс состоялся 22 августа 2017 года в блоге Яндекса для вебмастеров [1] и в блоге на Хабрахабре [2]. Реальные же изменения выдачи — были заметны и ранее, благодаря анализатору апдейтов выдачи «Пиксель Тулс».
Основная задача: улучшение качества выдачи по многословным низкочастотным запросам, по которым качество выдачи было низким (заведомо хуже, чем у Google — основного конкурента в рунете). В данный сегмент фраз часто попадают и голосовые запросы, заданные с переносных устройств на естественном языке (растущий спрос).
Что отличает данный алгоритм «Королёв» от предыдущего «Палеха» [3]? Добавление в общий набор факторов ранжирования, которые учитывают:
Схожесть того «смысла», который скрыт в поисковой фразе и «смысла» всего документа, а не только заголовка окна браузера Title.
Качество ответа документа на схожие по «смыслу» запросы пользователей.
Новая техническая реализация с расчётом ряда факторов на этапе индексирования и внедрением дополнительного индекса (см. ниже).
Чтобы понять, какой смысл* вкладывает пользователь в поисковый запрос и какой смысл раскрывается в тексте страницы — используется нейронная сеть. То есть, нейронная сеть как один из методов машинного обучения, лежит в основе вычисления ряда новых факторов, которые далее используются в алгоритме ранжирования.
* — далее мы будем употреблять это слово без кавычек, но важно понимать, что «смысл», который вычисляется с помощью компьютерного алгоритма и реальный смысл, который вкладывает в запрос/документ автор — неэквивалентные понятия.
В первую очередь, «Королёв» затрагивает ранжирование по длинным и/или редким поисковым запроса, которые часто задаются на естественном языке. Пример: [фильм где человек бежит из тюрьмы после очень долгой отсидки].
С точки зрения SEO-классификации это НЧ- и мНЧ-запросы, как правило, информационные, но возможных и коммерческие варианты, скажем: [купить штуку которая крутиться на пальцах]. Именно данный сегмент поисковых фраз носит название «длинного хвоста». На него приходится более 34% запросов из потока.
На текущий момент, для ряда запросов, по которым новая группа факторов получила высокую значимость, но поисковая система не до конца уверена в корректности его применения — проводится анкетирование пользователей (Рис. 1).
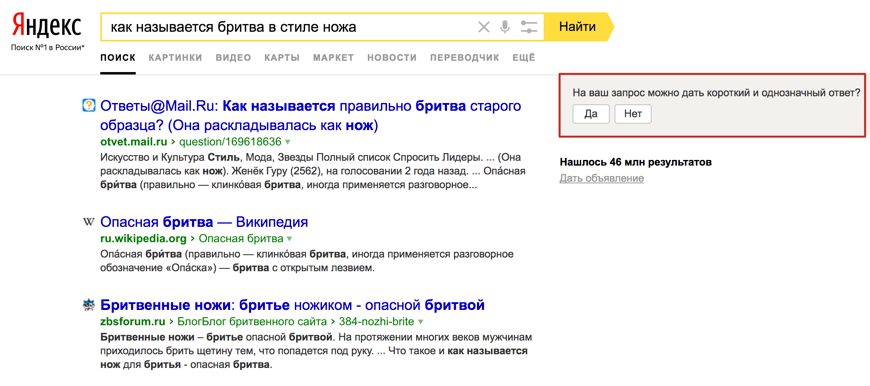
Рис. 1. Яндекс уточняет у пользователя, корректно ли была повышена значимость новой группы факторов для запроса
[как называется бритва в стиле ножа], какой ответ за вопрос является правильным и где он был найден?
С запросом, который приведён выше — Google справляется куда лучше, чем Яндекс (Рис. 2), но репрезентативная ли это картина? Для ответа на данный вопрос — выборка была увеличена и проведена ручная оценка качества выдачи по каждому из 127 запросов в режиме «Инкогнито». Исходный файл в TXT-формате, разделитель между колонками — точка с запятой. Данные собраны Викторией Левеной («Пиксель Плюс») через 3 дня после официального анонса.
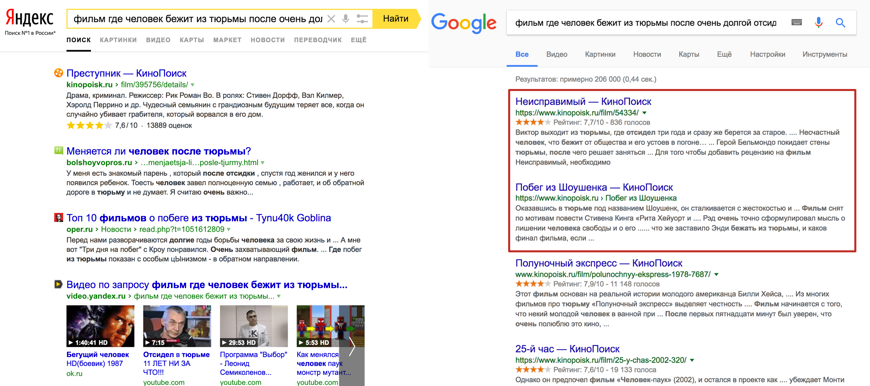
Рис. 2. Сравнение качества выдачи Яндекса и Google по запросу [фильм где человек бежит из тюрьмы после очень долгой отсидки].
В результате анализа SERP двух поисковых систем по пулу запросов, можно сделать следующие выводы:
Качество отработки алгоритмов «Королёв» и «RankBrain» — является соизмеримым.
В большинстве случаев (около 70% из выборки) — SERP оказывается схожим по качеству, что может говорить о близости самих алгоритмов реализации (напомним, что «RankBrain» был запущен в Google в октябре 2015 года).
Доля запросов, для которых алгоритмам удается успешно угадывать смысл, заданного на естественном языке составляет около 80% из выборки (полнота).
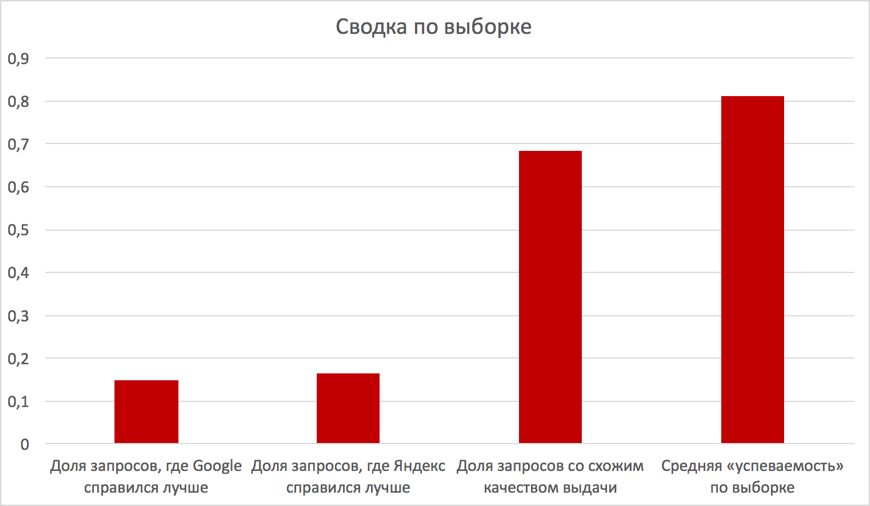
Рис. 3. Итоговые показатели работы алгоритмов Яндекса и Google по выборке мНЧ-фраз.
Как сказывается новый алгоритм ранжирования Яндекса на поисковой оптимизации (SEO)? Фактически, наиболее значимые изменения наблюдаются лишь для фраз, по которым нет достаточного количества релевантных ответов с классической точки зрения (нет страниц с точными вхождениями фраз и высокой частотой встречаемости термов). Это значит, что ранжирование по частотным запросам, по которым продвигается большинство коммерческих проектов претерпит минимальные изменения за счёт вклада новой группы факторов.
Как показывает практика, значительно чаще точное вхождение ключевой фразы (если оно есть) «побеждает» вклад новой группы факторов в ранжирование. Для примера рассмотрим запрос [ленивая кошка из монголии], который упоминался в презентации алгоритма как один из тех, по которому «Королёв» помогает найти короткий и правильный ответ — манула.
На иллюстрации ниже (Рис. 4) видно, что хотя алгоритм и угадывает смысл фразы (объектный ответ справа [4]), но выше в SERP оказываются документы с вхождениями слов из запроса и точным вхождением в тексте (те же анонсы), что наглядно подтверждает гипотезу. Это одна из причин, по которой примеры, которые публично анонсируют для иллюстрации отработки алгоритма перестают «работать» после пресс-релиза.
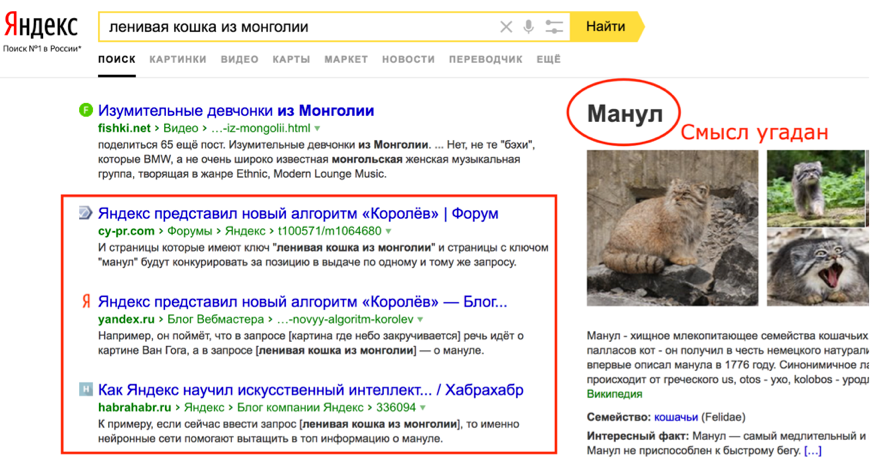
Рис. 4. Текущий «сломанный» вид SERP Яндекса по запросу из презентации.
Итого: если SEO-специалист провёл работы по улучшению «классических» факторов ранжирования, то URL будет хорошо ранжироваться по нужной НЧ-фразе. Здесь революции нет.
В коммерческом ранжировании, при прочих равных, новая группа факторов, конечно, может вносить некий вклад в ранжирование. Для улучшения значений по ней используются приёмы LSI-копирайтинга.
Для ускорения формирования ответа на запрос пользователя, используется не только итоговая формула ранжирования. Имеется несколько этапов, каждый из которых отбирает претендентов для следующего, более «тяжелого» алгоритма (Рис. 5).
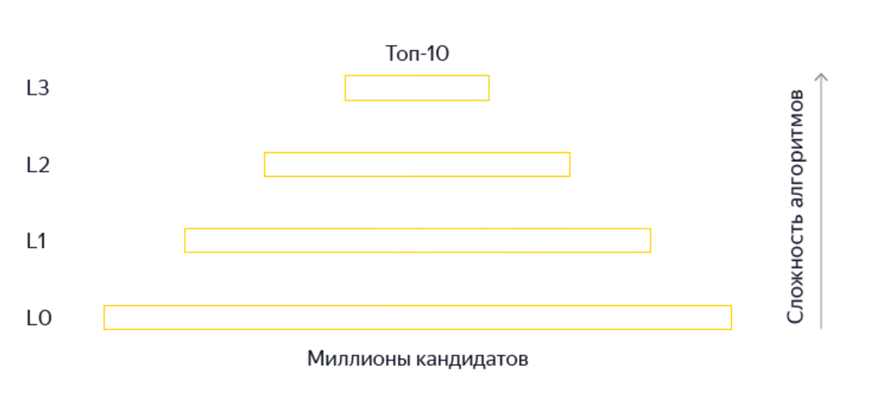
Рис. 5. Этапы ранжирования в поисковой системе Яндекс (фильтрация / кворум, Fast Rank, моном или частичное выполнение Матрикснет и итоговая формула релевантности).
Так как вычисление смысла для большого числа текстов на лету является длительной задачей, то данный процесс был сдвинут с финальной стадии ранжирования (как было в «Палехе») на этап индексирования.
Для ускорения финальной стадии ранжирования и освобождения вычислительных ресурсов был введён дополнительный индекс, который содержит уже вычисленную информацию об «ориентировочной» релевантности всех документов для всех одиночных слов и популярных пар слов, которые встречаются в запросах пользователей. Данный шаг позволил высвободить для поиска вычислительные мощности, которые необходимы для отработки сложных моделей, основанных на нейронных сетях (новый набор факторов).
Обучение нейронной сети производилось опираясь на многочисленные асессорские оценки и поведение пользователей. Напомним, что для увеличение общего числа оцененных пар запрос-документ, Яндексом был запущен публичный сервис «Толока» [5], который позволил кратно увеличить число асессоров и самих оценок (Рис. 6).
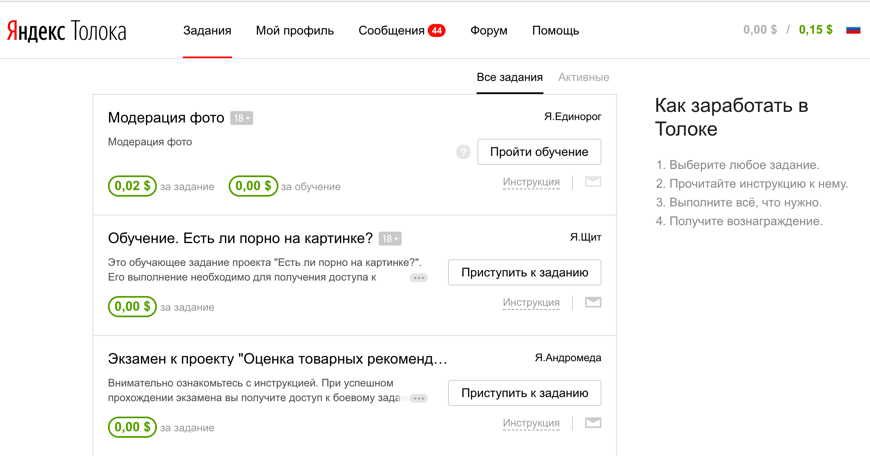
Рис. 6. Внешний вид сервиса Яндекс.Толока для исполнителя заданий (асессора).
Вторая причина причина по которой примеры, которые публично анонсируют перестают «работать» состоит именно в резком изменении паттерна поведения пользователей по ним и росте их популярности.
Машинное обучение используется в поиске Яндекса для построения формулы ранжирования начиная с 2009 года [6]. Итоговая формула и сейчас формируется благодаря методу Матрикснет, но ряд факторов в ней являются «непростыми» и сами получены с помощью нейронных сетей (машинного обучения). В каком-то смысле — матрёшка.
В дальнейшем планируется:
Улучшение качества оценки семантического соответствия (смысла) запроса и страницы.
Повышение полноты отработки.
Изменение логики фильтрации документов на стартовом этапе L0 (Рис. 5) — прохождения кворума.
Добавление к модели вектора персональных интересов пользователя (персонификация выдачи).
Вместе следим за развитием событий!
Поиск, который мы делаем вместе, 2017, https://yandex.ru/blog/company/korolev
Как Яндекс научил искусственный интеллект понимать смысл документов, 2017, https://habrahabr.ru/company/yandex/blog/336094/
Все алгоритмы Яндекса по годам, хронология 2007–2017, 2016–2017, https://pixelplus.ru/samostoyatelno/stati/prodvizhenie-saytov/algoritmy-ranzhirovaniya-yandex.html
Объектный ответ, 2015, https://yandex.ru/company/technologies/entity_search/
Яндекс.Толока, 2014, https://toloka.yandex.ru/
Матрикснет, 2009, https://yandex.ru/company/technologies/matrixnet




Комментариев пока что нет
Входим в число лучших компаний России в сферах интернет-рекламы и разработки сайтов по результатам самых авторитетных рейтингов















Нужна помощь с сайтом? Заполните форму, и наши менеджеры проконсультируют вас уже сегодня!


Уникальный тариф «Оборот», где доход агентства больше не зависит от визитов и позиций вашего сайта, а привязан исключительно к росту оборота вашей компании.
Тариф, который хотели сделать многие, но реализовали только мы.
Зарегистрироваться, используя e-mail: